Program directors (PDs) don’t have enough time to teach. A 2025 JGME analysis examining PDs workload across 14 specialties found that total weekly hours, spent on administrative, clinical supervision, and teaching fell from 51.3 to 44.2 between 2012 and 2021. Of those, the time spent teaching decreased with a corresponding increase in administrative activities.
The structured, developmental work of feedback, instruction, and deliberate practice with assessment creates a gap that has a direct cost for learners who need consistent, meaningful feedback to develop clinical competency.
AI in medical education is offering an opportunity to fill that gap, but available tools vary significantly in how they are built and what they can actually be trusted to do. The ones worth trusting share something in common: clinical expertise built in from the start, structured rubrics, and guardrails set by faculty.
Why the faculty workload problem keeps compounding
In 2019, the ACGME began reducing the protected time requirements that institutions must provide PDs and core faculty for non-clinical work. For example in internal medicine subspecialties, the aggregate protected time available across a program dropped from 60 hours per week in 2019 to 12 hours by 2023. That protected time is what allows for didactic teaching, resident assessment, curriculum development, and mentoring.
The result is that teaching and assessment are now competing for whatever time remains after clinical and administrative obligations are met. What that means in practice is a growing gap between supervision and development.
AI addresses this mismatch not by replacing educators, but by handling the parts of the assessment loop that don't require a faculty member to be present for every encounter: scaling consistent case exposure, scoring standardized encounters, generating structured feedback, and tracking performance across a cohort.
Why not all AI assessment tools can be trusted
The critical question is whether AI can assess clinical performance reliably enough to act on. And that depends on how the AI was built.
A 2024 prospective study in JMIR Medical Education offers a useful benchmark. 106 medical students completed history-taking exercises with a language model-powered simulated patient.
The researchers found that reliability improved when the AI was anchored in structured rubrics and clearly defined criteria. Where prompts were underspecified, agreement between AI and human raters dropped. The implication for PDs evaluating AI tools is direct: the reliability of AI-generated assessment is a function of the development process behind it — specifically, whether clinical expertise was built into the system from the start, or whether the AI is operating without structured guardrails.
How DDx puts this into practice
DDx was designed around a specific constraint: educators cannot scale their expertise through traditional methods without proportional increases in their time. What AI can do is make that scaling possible without adding additional time. Four capabilities address that directly.
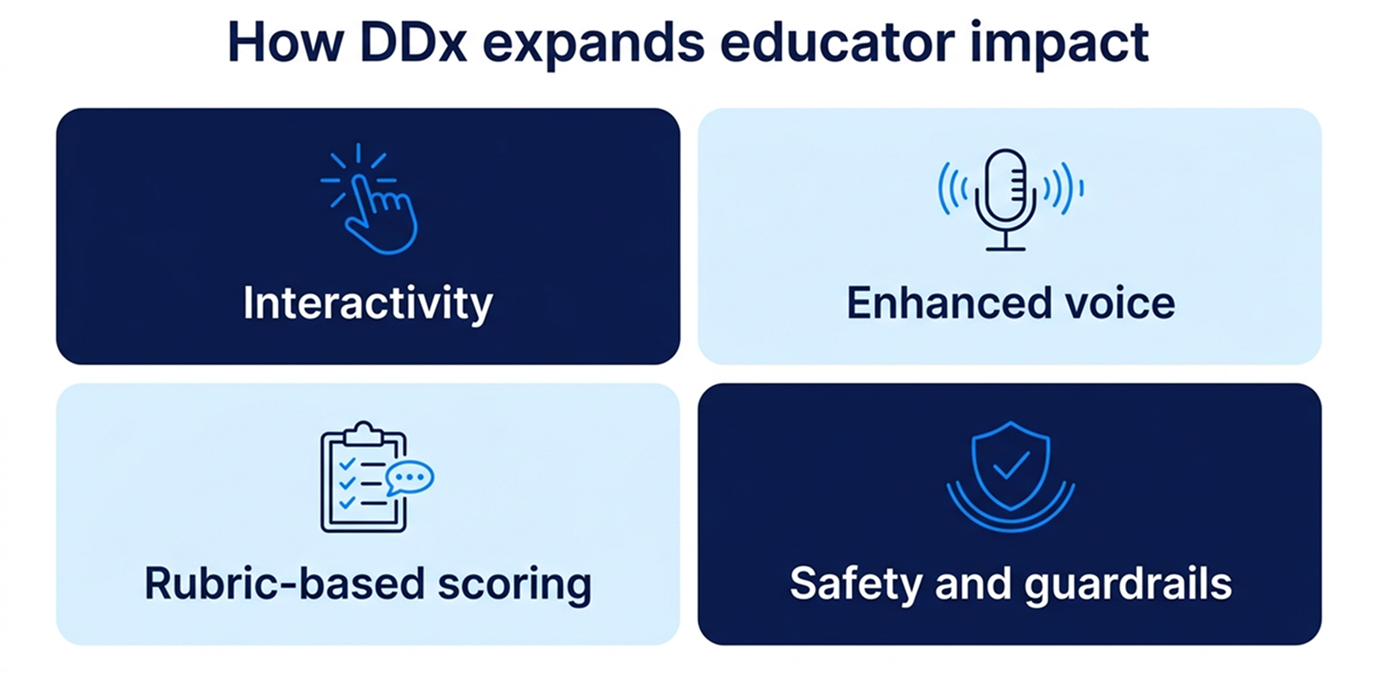
- Interactivity: learners engage in real clinical decision-making — gathering information, forming differentials, adapting as cases evolve — without requiring a faculty observer for every encounter.
- Enhanced voice: AI enables natural, conversational interactions with simulated patients and team members, allowing learners to develop communication and clinical reasoning skills in realistic contexts — competencies that are difficult to assess at scale through any other method.
- Rubric-based scoring: Performance is evaluated against structured clinical reasoning frameworks, mapped to critical competencies, including ACGME, AACOM, AAMC, ARC-PA, INACSL, NONPF or AACN. DDx applies it consistently across every learner, every time with no manual scoring or grading loop required for documented results.
- Safety and guardrails: DDx cases are written and peer-reviewed by subject matter experts before AI is introduced. AI operates within boundaries set by that expert-reviewed content, with built-in guardrails and ongoing human review to keep responses clinically accurate. DDx aligns with AAMC principles for responsible AI use, including disclosure, data privacy, and equitable access. On top of this, medical expert oversight and continuous monitoring ensure quality over time. Cases are reviewed, tested, and refined based on learner performance, feedback, and AI reliability.
The result: structured assessment criteria, mapped to national competency frameworks, applied consistently across an entire cohort without that faculty member in the room for every encounter. Authentic assessment at scale means more learners getting the structured feedback that builds clinical competency, not just the supervision that monitors it.
DDx is designed so programs can assess larger cohorts with greater consistency without proportional increases in faculty overhead. If you are evaluating how AI fits into your program's assessment workflow, we would welcome a 20-minute conversation.
Frequently asked questions
What is AI in medical education? AI in medical education refers to tools that use artificial intelligence to support teaching, assessment, and feedback in clinical training programs. The most relevant applications for faculty workload are those that can assess learner performance against structured clinical criteria and generate feedback at scale without requiring individual faculty review of each encounter.
How does AI reduce faculty workload in clinical assessment? By handling the assessment loop that traditionally requires direct faculty involvement: scoring performance against structured criteria and generating feedback. When AI is built on expert-reviewed cases and structured rubrics, it can perform these functions reliably at scale, allowing faculty to focus on supervision, remediation, and mentorship rather than routine scoring.
Can AI feedback replace faculty feedback in residency training? Not entirely, and that is not the right frame. AI feedback is well-suited to structured, documentable assessment: did the learner cover the relevant history, identify the appropriate differential, communicate clearly? Faculty judgment remains essential for clinical nuance and complex remediation. The value of AI is that it removes the routine tasks that currently consume faculty time before that judgment can be applied.
What should program directors look for when evaluating AI assessment tools? Start with the development process. Ask whether clinical subject matter experts write and review case content before AI is deployed. Ask whether the scoring rubric maps to your competency framework. Ask what guardrails prevent AI responses from drifting outside the intended clinical parameters. Platforms that cannot answer these questions clearly are transferring clinical accountability to a system that was not designed to carry it.
References
Holderried F, Stegemann-Philipps C, Herrmann-Werner A, Festl-Wietek T, Holderried M, Eickhoff C, Mahling M. A Language Model–Powered Simulated Patient With Automated Feedback for History Taking: Prospective Study. JMIR Med Educ 2024;10:e59213. URL: https://mededu.jmir.org/2024/1/e59213. DOI: 10.2196/59213
Turlington M, Newland J, Cahn M, Campbell B, Kavic SM. Where Does the Week Go? Parsing Trends in Program Director Workload. J Grad Med Educ. 2025 Apr;17(2):204-210. doi: 10.4300/JGME-D-24-00473.1. Epub 2025 Apr 15. PMID: 40417099; PMCID: PMC12096133.
Yuan CM, Young BY, Watson MA, Sussman AN. Programmed to Fail: The Decline of Protected Time for Training Program Administration. J Grad Med Educ. 2023 Oct;15(5):532-535. doi: 10.4300/JGME-D-23-00263.1. PMID: 37781435; PMCID: PMC10539136.